BERT・XLNet に学ぶ、言語処理における事前学習(第3版 電子書籍 136ページ)
- ダウンロード商品電子版 Only¥ 1,000
- 物販商品(自宅から発送)電子版+紙媒体支払いから発送までの日数:7日以内在庫なし¥ 1,500
- ダウンロード商品PyTorchハンズオン資料販売¥ 3,000
近年話題のBERT・XLNetなどの言語処理における事前学習モデルについて取り扱いました。論文や著者に近しい出展の実装など、極力一次ソースを元に言語処理の基本的な内容も加筆しながらまとめた形になります。 【第2版追記】 第2版の刊行にあたって、第2章の記述の大幅の見直しを行いました。具体的にはself-attentionに関する研究[2017]、Decomposable Attention[2016]、Reformer[2020]を追記し、Transformerがより多面的に理解できるように加筆を行いました。 【第3版追記】 第3版の刊行にあたって、TransformerのGraph Neural Networkとの関連性について2-7節に追記を行いました。 ※ 印刷版は第二版時のものになりますので、その代わりに下記の印刷版もセットでお送りできればと思います。 https://lib-arts.booth.pm/items/1847458

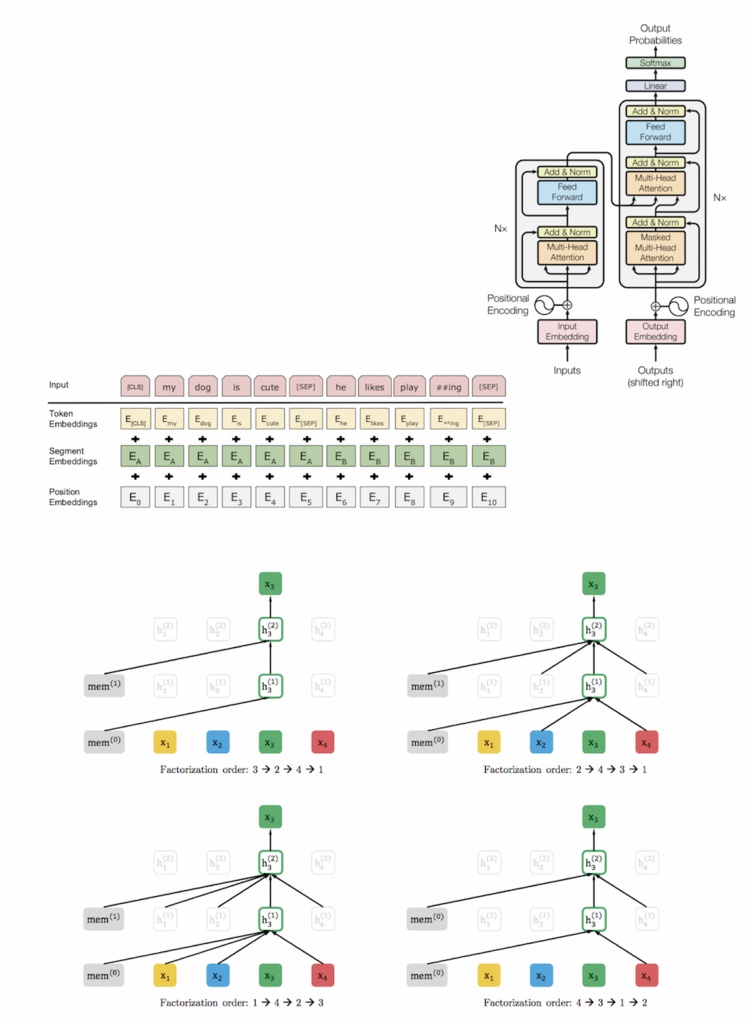















近年話題のBERT・XLNetなどの言語処理における事前学習モデルについて取り扱いました。論文や著者に近しい出展の実装など、極力一次ソースを元に言語処理の基本的な内容も加筆しながらまとめた形になります。
【第2版追記】
第2版の刊行にあたって、第2章の記述の大幅の見直しを行いました。具体的にはself-attentionに関する研究[2017]、Decomposable Attention[2016]、Reformer[2020]を追記し、Transformerがより多面的に理解できるように加筆を行いました。
【第3版追記】
第3版の刊行にあたって、TransformerのGraph Neural Networkとの関連性について2-7節に追記を行いました。
※
印刷版は第二版時のものになりますので、その代わりに下記の印刷版もセットでお送りできればと思います。
https://lib-arts.booth.pm/items/1847458